The Subsumption Model Trail
Introduction
Considering the demo code from the Core Model Trail, imagine that instead of just looking for food objects, we want now a mechanism for searching for both crystals and food. Imagine the following specifications:
- While the energy resources are higher than 40%, the creature should only collect food if apples and nuts are obstructing their way. In this situation, the creature should search for the crystals necessary to complete their leaflet and trade these crystals for points.
- If the energy level decreases below 40%, the creature should look for the closest food they are aware and just collecting crystals if they are obstructing their way.
In the original Core Model Trail exercise, there is just a single object to move to, the closest apple. Imagining a similar mechanism to grasp jewels, we might have, at least two different moves to consider: the closest apple or the closest jewel. These two actions, though, affect the same actuator: legs. There might be, then, a way to give priority to one of these behaviors such that the correct value can be sent to the actuator. In a generalization of this idea, we might conceive a situation where multiple behaviors are supposed to propose a different value to be sent to this actuator. One traditional way of dealing with this problem is using a Subsumption Architecture.
Subsumption Architecture
The Subsumption Architecture is a generic name for a family of computational architectures used in intelligent control (particularly in robotics), developed by Rodney Brooks in the 90's, which gave rise to the whole Behavior-based Robotics research field. Brooks proposal was developed under the context of mobile robotics, and was a reaction against the research program on Artificial Intelligence, which was suffering from a set of limitations. The traditional operational cycle of an intelligent control systems following the Artificial Intelligence paradigm was that presented in figure 1.
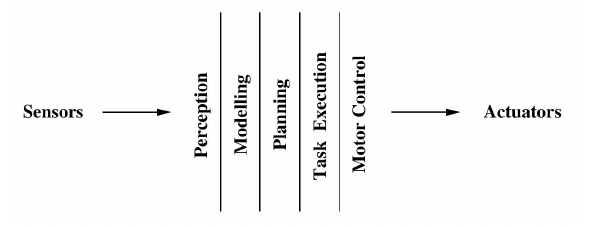
Figure 1: Traditional Intelligent Control Systems - adapted from (Brooks, 1986)
According to this paradigm, information was processed by a kind of pipeline, where sensor data was first processed by a Perception module, giving rise to a an internal model in the Modeling module. This model was used by a Planning Module, which would generate a plan. This plan would feed a Task Execution Module, which would generate control signals by a Motor Control Module, which would be sent to system actuators. Even though this operational cycle was adequate for small toy problem applications, Brooks pointed out the lack of scalability of such architecture. When the number of considered behaviors started to increase, the system complexity started to grow into many problems and the cycle started to become unfeasible.
Alternatively, instead of a serial pipeline, Brooks proposed a parallel strategy, as depicted in figure 2. In this new approach, named Subsumption Architecture, new behaviors could be developed in an isolated way and further integrated in the overall architecture. All behaviors used to compete to each other in order to have access to the actuators.

Figure 2 - Control Scheme in a Subsumption Architecture - adapted from (Brooks, 1986)
An instance of a Subsumption Architecture is presented in figure 3. This figure illustrates a typical application in the field of mobile robotics.
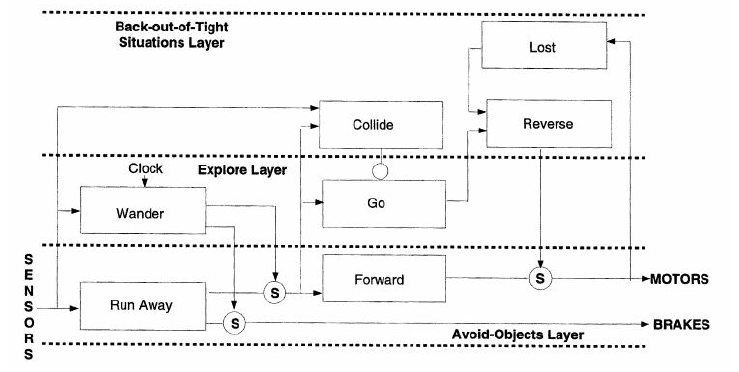
Figure 3 - An Example of a Subsumption Architecture - adapted from (Arkin, 1998)
The architecture is composed by a set of behaviors connected to each other, in which some behaviors are fed by sensors, generating new signals, which will feed other behaviors, until they generate actuators signals. In the original Brooks proposal Brooks, (1986), each behavior is a finite state machine, augmented with some instance variables. Each behavior has a number of input lines and a number of output lines. These lines are used to send and receive messages from sensors and other behaviors up to actuators. The most recently arrived message is always available for inspection. Messages can be lost if a new one arrives on an input line before the last one was processed. There is a distinguished input in each module which causes the reset of the module, returning the internal state machine to an initial state. There are also two different kinds of nodes which can be used to connect different behaviors: inhibitor nodes and suppress nodes. These two nodes are used when there are two signals which compete to post a message in the same line, as shown in figure 4.
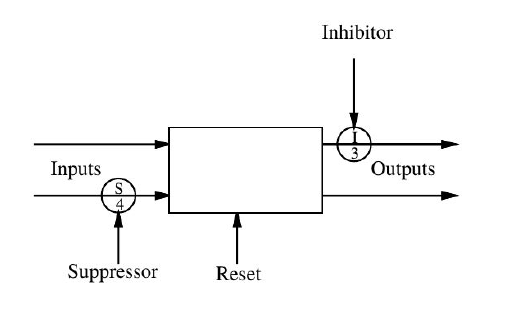
Figure 4 - Detail of a Behavior in Subsumption Architecture - adapted from (Brooks, 1986)
The inner workings of inhibitory and suppression nodes are very close to each other, but they are different. In both nodes, there are two inputs, and one of them is dominant over the second. The whole scheme is a message-passing scheme. An inhibitory node will receive a message at its dominant input, and this will cause the node to block, for a determined amount of time, any further messages arriving at the other input. The behavior of the suppression node is quite similar, but slightly different. A suppression node, in receiving a message at its dominant input, will block, for a specific amount of time, any further messages arriving at the other input. But, additionally to that, it will propagate the received message at the dominant input to its output.
The original Brooks proposal used to require a parameter specifying the amount of time an inhibitory or a suppression node will hold. After the original work, Connell, (1989) proposed a slightly modified version of the Subsumption Architecture, where instead of sending event-based commands as messages, the behaviors would send a continuous "burst" of messages. The modification introduced by Connell started to become popular, and gained wide acceptation within the community, becoming the canonical implementation of the Subsumption Architecture since so far. Connell’s modification made the inhibitory node obsolete, and since that, most Subsumption Architectures started to use just suppression nodes. Since suppression nodes were the only kind of connector node between two lines, some authors decided to even not show the suppression node explicitly in their architectural notation, as shown in figure 5.
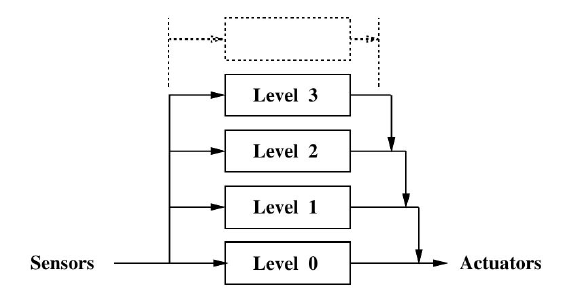
Figure 5 - Layered Control in a Subsumption Architecture - adapted from (Brooks, 1986)
This new notation made explicit another important feature of a Subsumption Architecture, which is its segmentation into layers. Layers are related exactly to which behavior is feeding the dominant input of a suppression node. The behavior feeding the non-dominant input is on a lower layer. The behavior feeding the dominant input is on a higher layer. The dominant input of a suppression node started to be notated in the architecture as an arrow arriving at a straight line, as pointed out in figure 5. It is important to notice that even though the suppression nodes are not shown explicitly, they are still there.
The field of Behavior-based Robotics evolved a lot since the introduction of Subsumption Architecture. Many variations started to appear, including Motor Schemas and other reactive architectures (Arkin, 1998), but the Subsumption is still very popular, and its modern versions usually comprise a Subsumption Architecture hybridized with some sort of extension. An example is the SSS architecture, illustrated in 6.
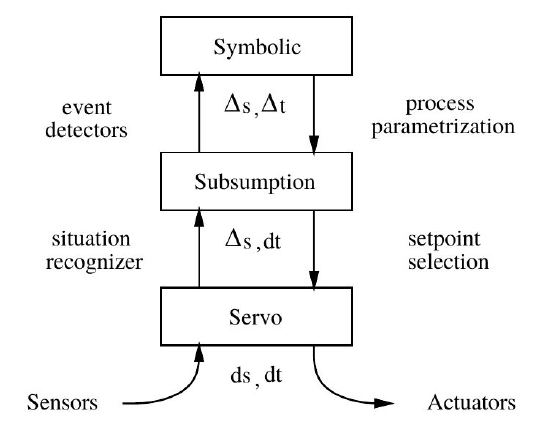
Figure 6 - The SSS Subsumption Architecture
In the SSS (Servo-Subsumption-Symbolic) Architecture (Connell, 1992), a Subsumption Architecture is hybridized with a Symbolic rule-based interpreter in order to combine features from a conventional servo-system, with a Subsumption Architecture, with a rule-based symbolic AI system. This hybridization tries to integrate what is best in each kind of architecture. Servo-controllers have trouble with many real-world phenomena, which are difficult to be appropriately modeled within control theory models. Subsumption systems are more flexible to deal with these issues, but are also limited by the reactive paradigm. Event though they are able to generate very easily, quite complex kinds of behavior, they are not able to plan how to achieve future goals, and anticipate potential (and avoidable) hazards. This is basically what symbolic rule-based systems are able to provide.
Dynamic Subsumption
One possible shortcoming to list in Classical Subsumption Architecture is that suppression nodes have fixed dominant and non-dominant nodes. This means that once a behavior is in a higher level level, it will always have priority in setting up its behavior. Even though this is desirable in some situations, it is always possible to envision situations in which this priority should be reversed, at least in special occasions. This is not possible in classical Subsumption Architecture.
To deal with this difficulty, some authors (Hamadi et al., 2010; Heckel and Youngblood, 2010; Nakashima and Noda, 1998) proposed a Dynamic Subsumption scheme, in which there is no fixed dominant input in a suppression node, but this dominance can be changed dynamically in time, according to specific situations.
There are different implementations of this Dynamical Subsumption idea, but a very simple comprehension of the idea can be taken from figure 7.
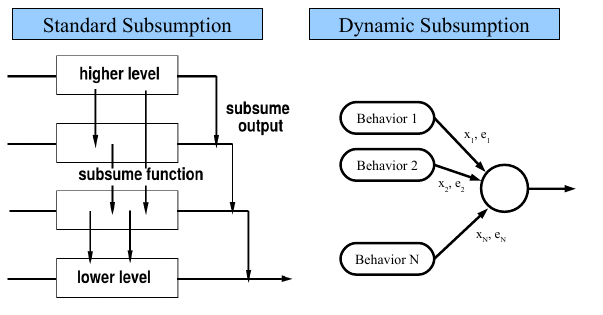
Figure 7 - The Dynamical Subsumption Scheme
In the left side of this figure, we can see a standard Subsumption Architecture, with its fixed priority among behaviors. On the right side, we can see how a Dynamical Subsumption can be implemented. Together with the standard control message xi , there comes together an evaluation tag ei which is dynamically generated by the own behavior. So, instead of choosing the output value x using a fixed set of priorities, the dynamical mechanism simply chooses the xi which has the greatest ei value. This ei value can be generated dynamically according to the systems’ requirements.
Building a Subsumption Architecture with CST
Now, holding back our original problem, how can we build a Subsumption Architecture with CST ? Let's remember some points from our Core Model Trail. You might remember that in our WS3DApp demo, a very peculiar situation holds: the hands motor codelet receives commands from just one behavior codelet: the EatClosestApple. The legs motor codelet, though, receives commands from two distinct behavior codelets: the GoToClosestApple codelet and the Forage codelet. This could cause a potential problem, if both codelets suggest different commands at each time: the legsMO might just hold the last command sent by the behavior codelets, and this might cause a running condition, a known problem in multi-thread programming. Fortunately, in our example, this doesn't happen, because the Forage codelet only suggests an action if the list of known apples is empty, and the the GoToClosestApple only suggests an action if there is at least one known apple. This creates a mutual exclusion situation wich avoids the running condition to happen. But now, while extending our source code to other behaviors, we cannot count with this fortunate situation anymore, we need to solve this. In order to solve this, CST provides the MemoryContainer class, which is basically a boosted MemoryObject, where multiple codelets might write at the same time, and the MemoryContainer will hold separate objects for input, and a standard mechanism for output.
The Memory Container
The mechanism of a MemoryContainer can be understood by the figure below:
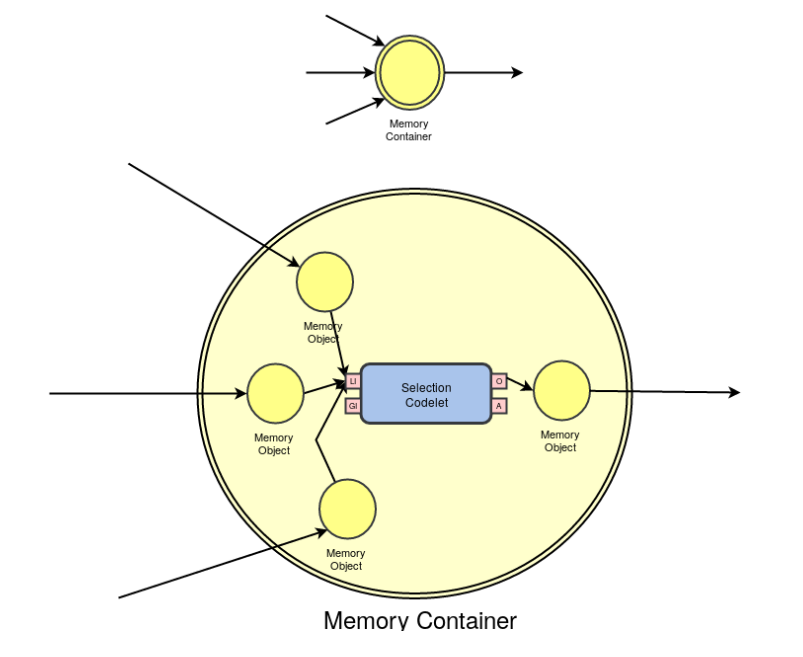
The Selection Codelet which is implicitly embedded into a MemoryContainer just selects the MemoryObject within the MemoryContainer which holds the maximum eval field, which can be set by the codelet which generated the MemoryObject. With the MemoryContainer mechanism, many different behavior codelets might write within the Container, but using its setI method, and while using the getI method to have access to its inner object, it will return the object with the highest eval value, which can be set with the setEval method.
There are some differences, though, while using Memory Containers instead of Memory Objects, which you might be aware. The first time you do a setI(Object) in a MemoryContainer, it will return a number which should be preserved for future uses of the MemoryContainer. In future uses, instead of using the setI(Object), you should use the setI(Object, index), where index is the number returned by the first call to setI(Object). This guarantees that you are using always the same internal MemoryObject within the MemoryContainer. As an output, the getI() method will always return the inner MemoryObject with the maximum value for the eval parameter. The eval parameter can be set directly with the setI(Object, eval, index) version of the setI method. For more information on how to use Memory Containers, please take a look on the source code of the MemoryContainer class.
Exercise
As an exercise, try to extend the CoreModelTrail by using the specifications provided in the beginning of the Subsumption Trail, by implementing jewel collection codelets in the same direction as the apple collection codelets. In order to implement a subsumption architecture, use the MemoryContainer class, as explained later.
References
(Arkin 1998) Arkin, R. C. Behavior-based robotics. MIT press, 1998.
(Brooks 1986) Brooks, R. “A robust layered control system for a mobile robot”. In: IEEE journal on robotics and automation 2.1 (1986), pp. 14–23.
(Connell 1989) Connell, J. H. “A behavior-based arm controller”. In: IEEE Transactions on Robotics and Automation 5.6 (1989), pp. 784–791.
(Connell 1992) Connell, J. H. “SSS: A hybrid architecture applied to robot navigation”. In: Robotics and Automation, 1992. Proceedings., 1992 IEEE International Conference on. IEEE. 1992, pp. 2719–2724.
(Hamadi et al. 2010) Hamadi, Y., Jabbour, S., and Saïs, L. “Learning for dynamic subsumption”. In: International Journal on Artificial Intelligence Tools 19.04 (2010), pp. 511–529.
(Heckel et al. 2010) Heckel, F. W. and Youngblood, G. M. “Multi-Agent Coordination Using Dynamic Behavior-Based Subsumption.” In: Sixth Artificial Intelligence and Interactive Digital Entertainment Conference - AIIDE. 2010.
(Nakashima et al. 1998) Nakashima, H. and Noda, I. “Dynamic Subsumption Architecture for Programming Intelligent Agents”. In: Proceedings of the 3rd International Conference on Multi Agent Systems - ICMAS. IEEE Computer Society. 1998, pp. 190–197.